
Use a Jupyter notebook for Kedro project experiments¶
This page explains how to use a Jupyter notebook to explore elements of a Kedro project. It shows how to use kedro jupyter notebook to set up a notebook that has access to the catalog, context, pipelines and session variables of the Kedro project so you can query them.
This page also explains how to use line magic to display a Kedro-Viz visualisation of your pipeline directly in your notebook.
Example project¶
The example adds a notebook to experiment with the retired pandas-iris starter. As an alternative, you can follow the example using a different starter, such as spaceflights-pandas or just add a notebook to your own project.
We will assume the example project is called iris, but you can call it whatever you choose.
Loading the project with kedro jupyter notebook¶
Navigate to the project directory (cd iris) and issue the following command in the terminal to launch Jupyter:
kedro jupyter notebook
You’ll be asked if you want to opt into usage analytics on the first run of your new project. Once you’ve answered the question with y or n, your browser window will open with a Jupyter page that lists the folders in your project:
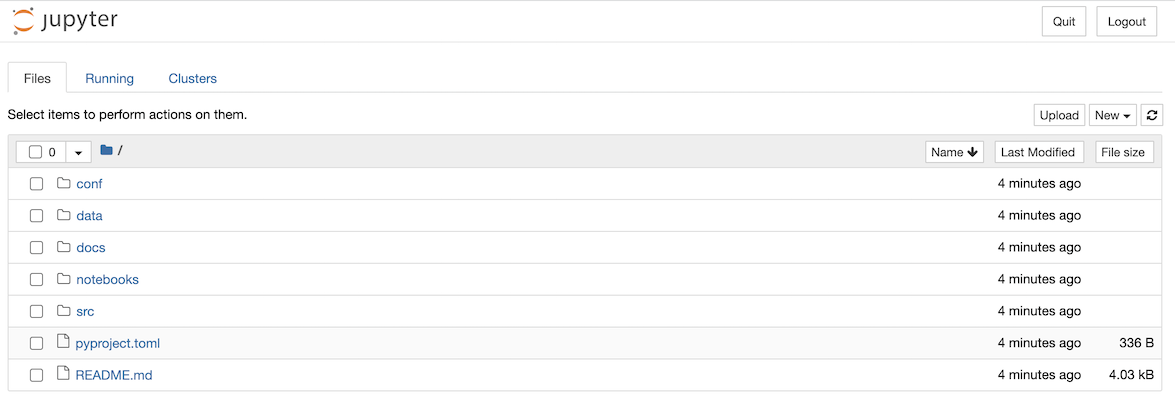
You can now create a new Jupyter notebook using the New dropdown and selecting the Kedro (iris) kernel:
This opens a new browser tab to display the empty notebook:

We recommend that you save your notebook in the notebooks folder of your Kedro project.
What does kedro jupyter notebook do?¶
The kedro jupyter notebook command launches a notebook with a customised kernel that has been extended to make the following project variables available:
catalog(typeDataCatalog): Data Catalog instance that contains all defined datasets; this is a shortcut forcontext.catalogcontext(typeKedroContext): Kedro project context that provides access to Kedro’s library componentspipelines(typedict[str, Pipeline]): Pipelines defined in your pipeline registrysession(typeKedroSession): Kedro session that orchestrates a pipeline run
In addtion, it also runs %load_ext kedro.ipython automatically when you launch the notebook.
Note
If the Kedro variables are not available within your Jupyter notebook, you could have a malformed configuration file or missing dependencies. The full error message is shown on the terminal used to launch kedro jupyter notebook or run %load_ext kedro.ipython in a notebook cell.
Loading the project with the kedro.ipython extension¶
A quick way to explore the catalog, context, pipelines, and session variables in your project within a IPython compatible environment, such as Databricks notebooks, Google Colab, and more, is to use the kedro.ipython extension.
This is tool-independent and useful in situations where launching a Jupyter interactive environment is not possible. You can use the %load_ext line magic to explicitly load the Kedro IPython extension:
In [1]: %load_ext kedro.ipython
If you have launched your interactive environment from outside your Kedro project, you will need to run a second line magic to set the project path.
This is so that Kedro can load the catalog, context, pipelines and session variables:
In [2]: %reload_kedro <project_root>
The Kedro IPython extension remembers the project path so that future calls to %reload_kedro do not need to specify it:
In [1]: %load_ext kedro.ipython
In [2]: %reload_kedro <project_root>
In [3]: %reload_kedro
Exploring the Kedro project in a notebook¶
Here are some examples of how to work with the Kedro variables. To explore the full range of attributes and methods available, see the relevant API documentation or use the Python dir() function, for example dir(catalog).
catalog¶
catalog can be used to explore your project’s Data Catalog using methods such as catalog.list, catalog.load and catalog.save.
For example, add the following to a cell in your notebook to run catalog.list:
catalog.list()
When you run the cell:
['example_iris_data',
'parameters',
'params:example_test_data_ratio',
'params:example_num_train_iter',
'params:example_learning_rate'
]
Next try the following for catalog.load:
catalog.load("example_iris_data")
The output:
INFO Loading data from 'example_iris_data' (CSVDataset)...
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosa
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 virginica
146 6.3 2.5 5.0 1.9 virginica
147 6.5 3.0 5.2 2.0 virginica
148 6.2 3.4 5.4 2.3 virginica
149 5.9 3.0 5.1 1.8 virginica
Now try the following:
catalog.load("parameters")
You should see this:
INFO Loading data from 'parameters' (MemoryDataset)...
{'example_test_data_ratio': 0.2,
'example_num_train_iter': 10000,
'example_learning_rate': 0.01}
Note
If you enable versioning you can load a particular version of a dataset, e.g. catalog.load("example_train_x", version="2021-12-13T15.08.09.255Z").
context¶
context enables you to access Kedro’s library components and project metadata. For example, if you add the following to a cell and run it:
context.project_path
You should see output like this, according to your username and path:
PosixPath('/Users/username/kedro_projects/iris')
You can find out more in the API documentation of KedroContext.
pipelines¶
pipelines is a dictionary containing your project’s registered pipelines:
pipelines
The output will be a listing as follows:
{'__default__': Pipeline([
Node(split_data, ['example_iris_data', 'parameters'], ['X_train', 'X_test', 'y_train', 'y_test'], 'split'),
Node(make_predictions, ['X_train', 'X_test', 'y_train'], 'y_pred', 'make_predictions'),
Node(report_accuracy, ['y_pred', 'y_test'], None, 'report_accuracy')
])}
You can use this to explore your pipelines and the nodes they contain:
pipelines["__default__"].all_outputs()
Should give the output:
{'y_pred', 'X_test', 'y_train', 'X_train', 'y_test'}
session¶
session.run allows you to run a pipeline. With no arguments, this will run your __default__ project pipeline sequentially, much as a call to kedro run from the terminal:
session.run()
You can also specify the following optional arguments for session.run:
Argument name |
Accepted types |
Description |
|---|---|---|
|
|
Construct the pipeline using nodes which have this tag attached. A node is included in the resulting pipeline if it contains any of those tags |
|
|
An instance of Kedro |
|
|
Run nodes with specified names |
|
|
A list of node names which should be used as a starting point |
|
|
A list of node names which should be used as an end point |
|
|
A list of dataset names which should be used as a starting point |
|
|
A list of dataset names which should be used as an end point |
|
|
A mapping of a dataset name to a specific dataset version (timestamp) for loading. Applies to versioned datasets |
|
| pipeline_name | str | Name of the modular pipeline to run. Must be one of those returned by the register_pipelines function in src/<package_name>/pipeline_registry.py |
You can execute one successful run per session, as there’s a one-to-one mapping between a session and a run. If you wish to do more than one run, you’ll have to run %reload_kedro line magic to get a new session.
Kedro line magics¶
Line magics are commands that provide a concise way of performing tasks in an interactive session. Kedro provides several line magic commands to simplify working with Kedro projects in interactive environments.
%reload_kedro line magic¶
You can use %reload_kedro line magic within your Jupyter notebook to reload the Kedro variables (for example, if you need to update catalog following changes to your Data Catalog).
You don’t need to restart the kernel for the catalog, context, pipelines and session variables.
%reload_kedro accepts optional keyword arguments env and params. For example, to use configuration environment prod:
%reload_kedro --env=prod
For more details, run %reload_kedro?.
%load_node line magic¶
Note
This is still an experimental feature and is currently only available for Jupyter Notebook (>7.0), Jupyter Lab, IPython, and VSCode Notebook. If you encounter unexpected behaviour or would like to suggest feature enhancements, add it under this github issue.
You can load the contents of a node in your project into a series of cells using the %load_node line magic. To use %load_node, the node you want to load needs to fulfil two requirements:
The node needs to have a name
The node’s inputs need to be persisted
The section about creating nodes with names explains how to ensure your node has a name. By default, Kedro saves data in memory. To persist the data, you need to declare the dataset in the Data Catalog.
Note
The node name needs to be unique within the pipeline. In the absence of a user defined name, Kedro generates one using a combination of the function name, inputs and outputs.
The line magic will load your node’s inputs, imports, and body:
%load_node <my-node-name>
Click to see an example.

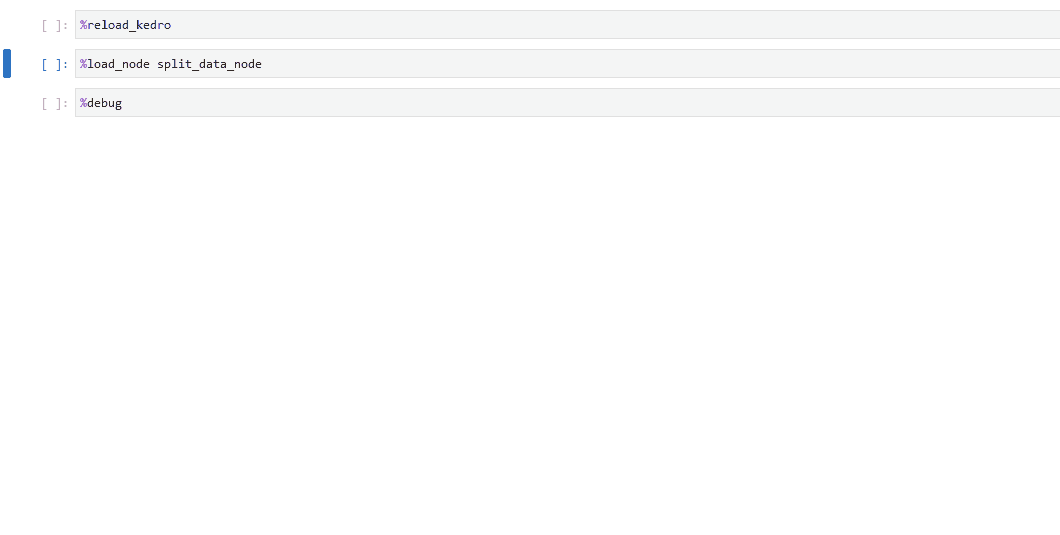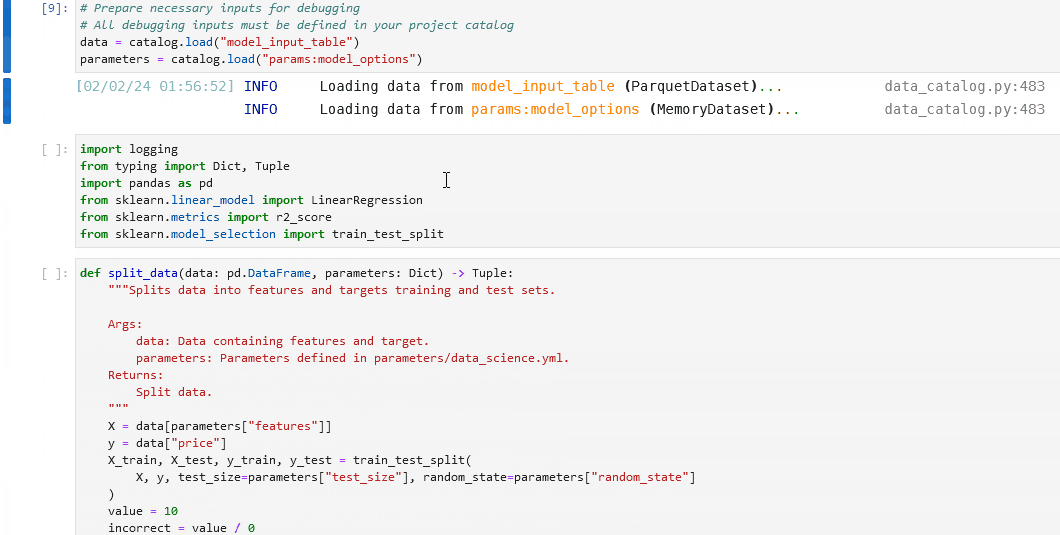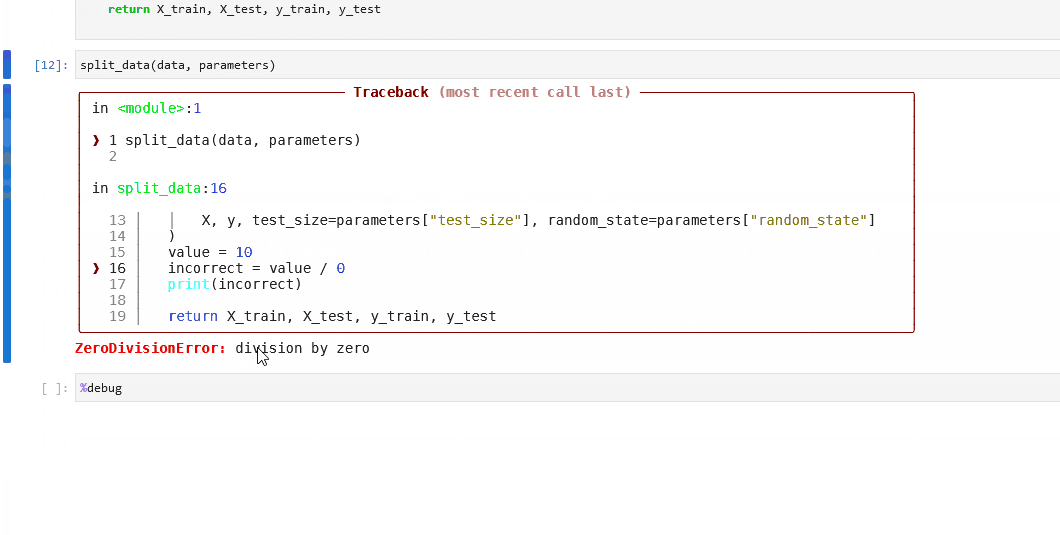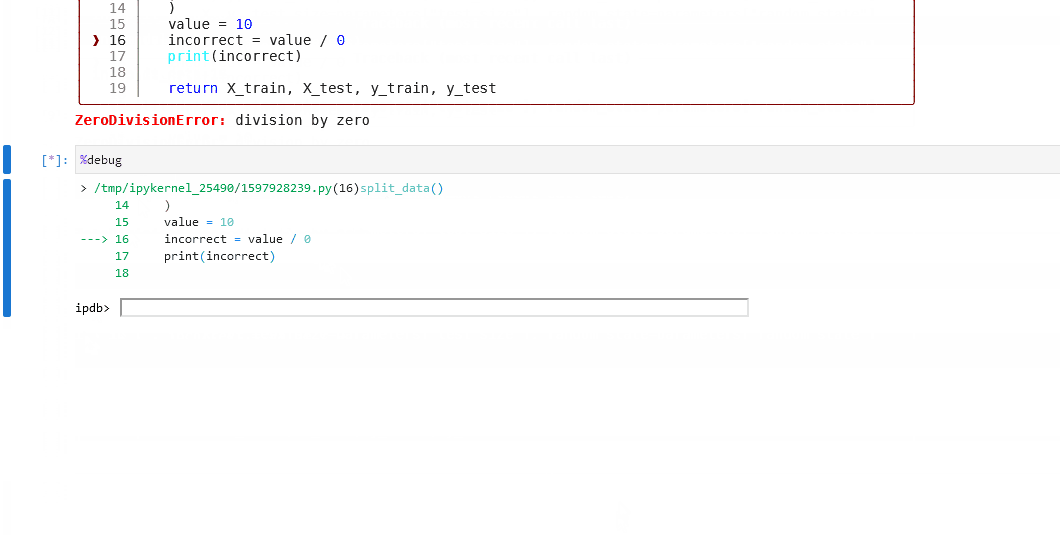
To be able to access your node’s inputs, make sure they are explicitly defined in your project’s catalog.
You can then run the generated cells to recreate how the node would run in your pipeline. You can use this to explore your node’s inputs, behaviour, and outputs in isolation, or for debugging.
When using this feature in Jupyter Notebook you will need to have the following requirements and minimum versions installed:
ipylab>=1.0.0
notebook>=7.0.0
%run_viz line magic¶
Note
If you have not yet installed Kedro-Viz for the project, run pip install kedro-viz in your terminal from within the project directory.
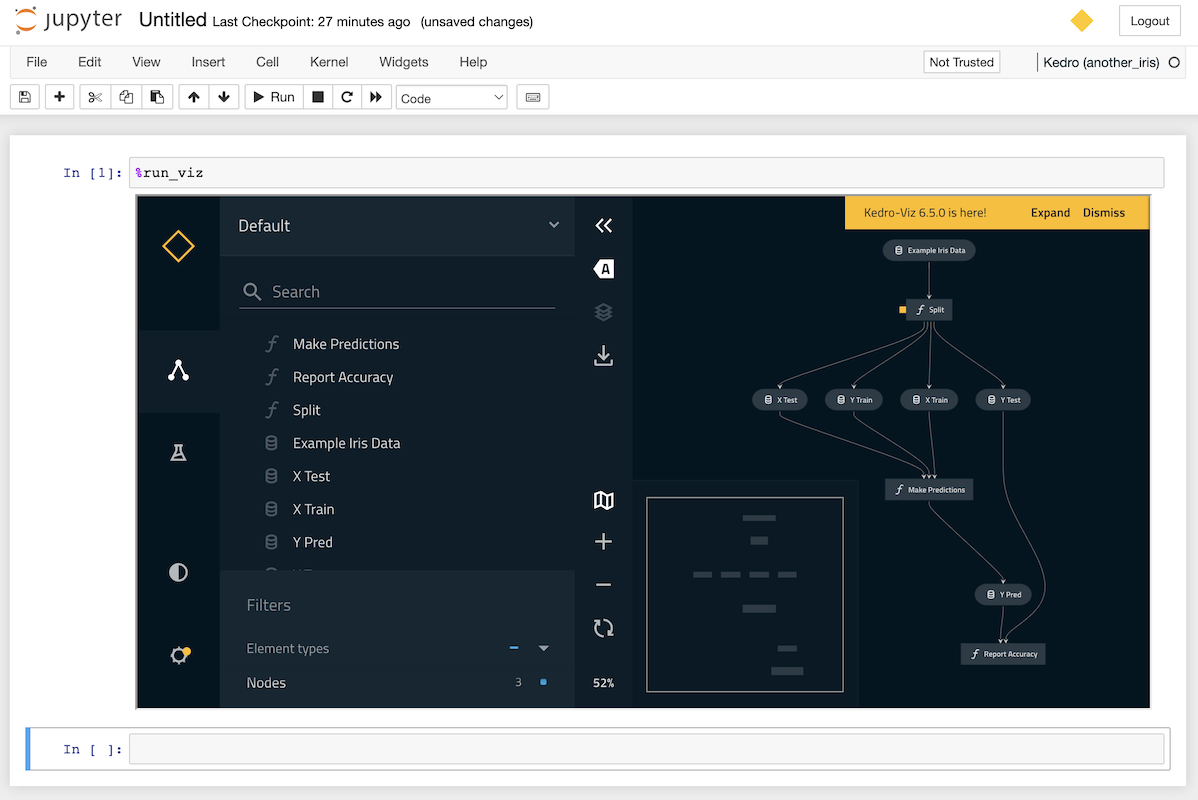
You can display an interactive visualisation of your pipeline directly in your notebook using the %run_viz line magic from within a cell:
%run_viz
Debugging a Kedro project within a notebook¶
You can use the built-in %debug line magic to launch an interactive debugger in your Jupyter notebook. Declare it before a single-line statement to step through the execution in debug mode. You can use the argument --breakpoint or -b to provide a breakpoint. Alternatively, use the command with no arguments after an error occurs to load the stack trace and begin debugging.
The following sequence occurs when %debug runs after an error occurs:
The stack trace of the last unhandled exception loads.
The program stops at the point where the exception occurred.
An interactive shell where the user can navigate through the stack trace opens.
You can then inspect the value of expressions and arguments, or add breakpoints to the code.
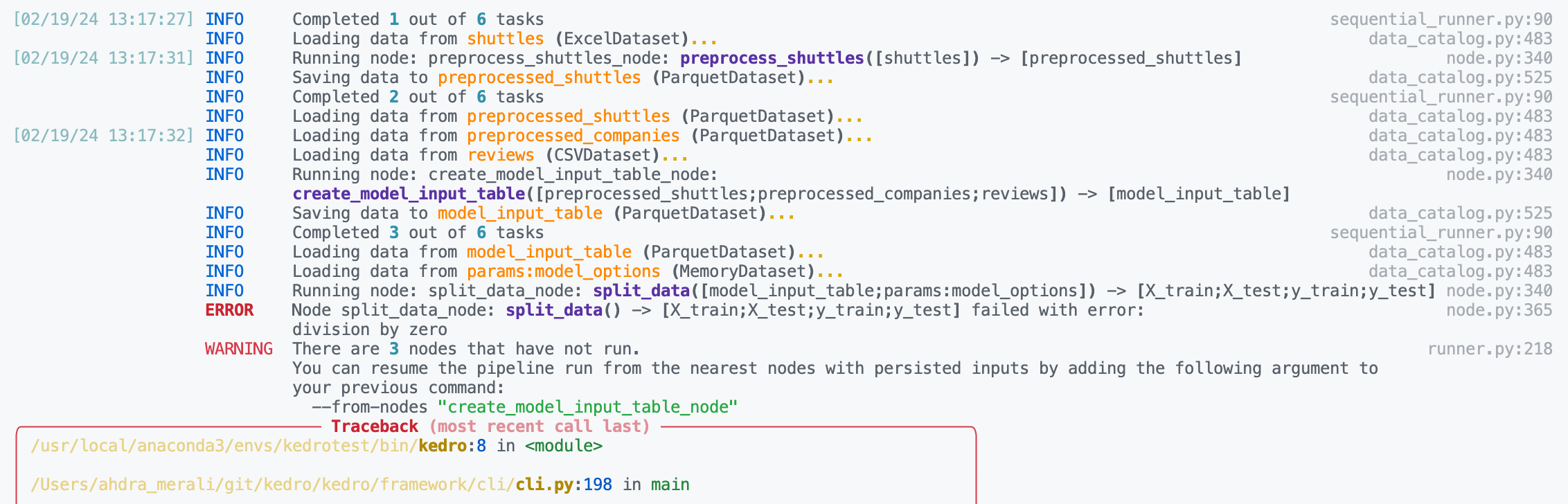
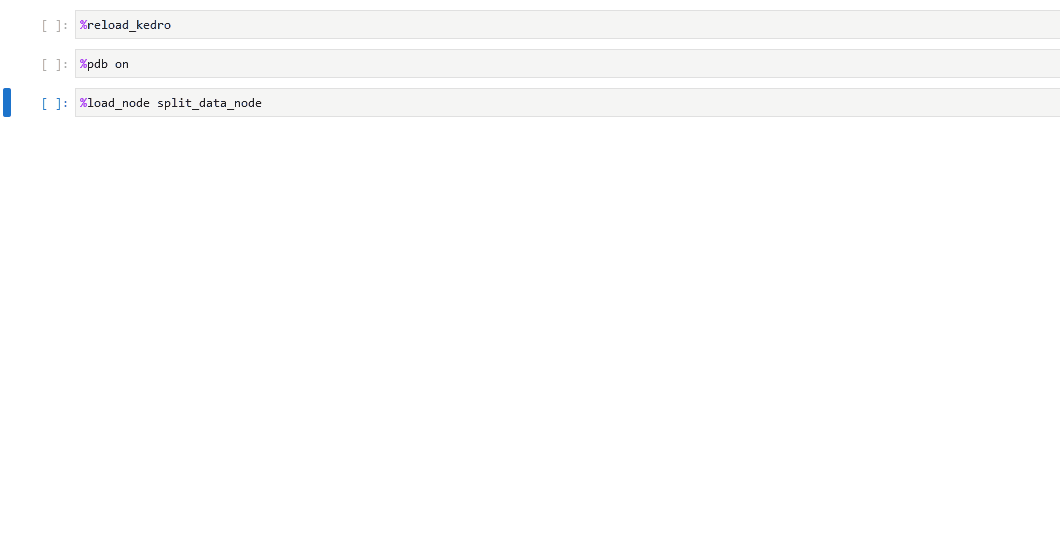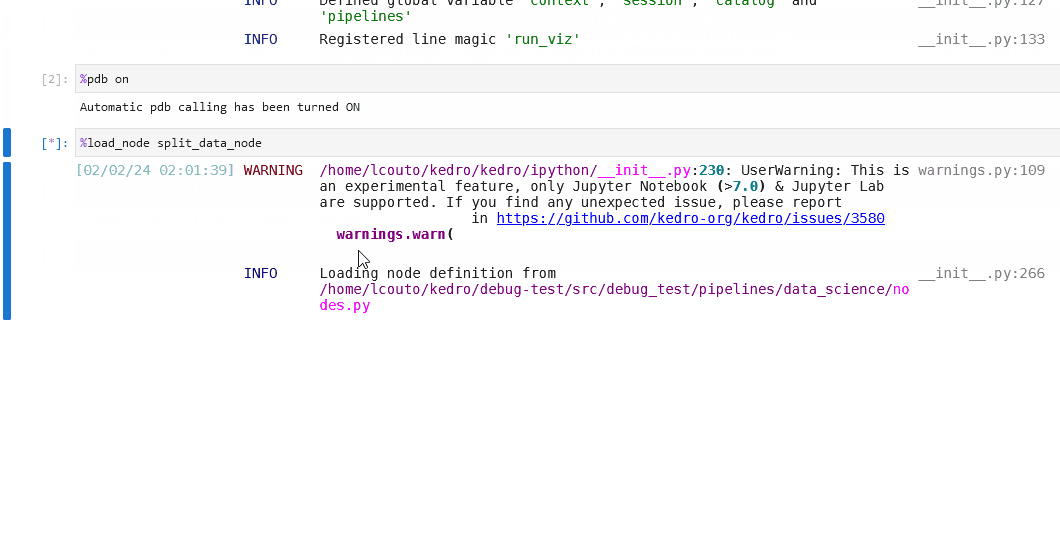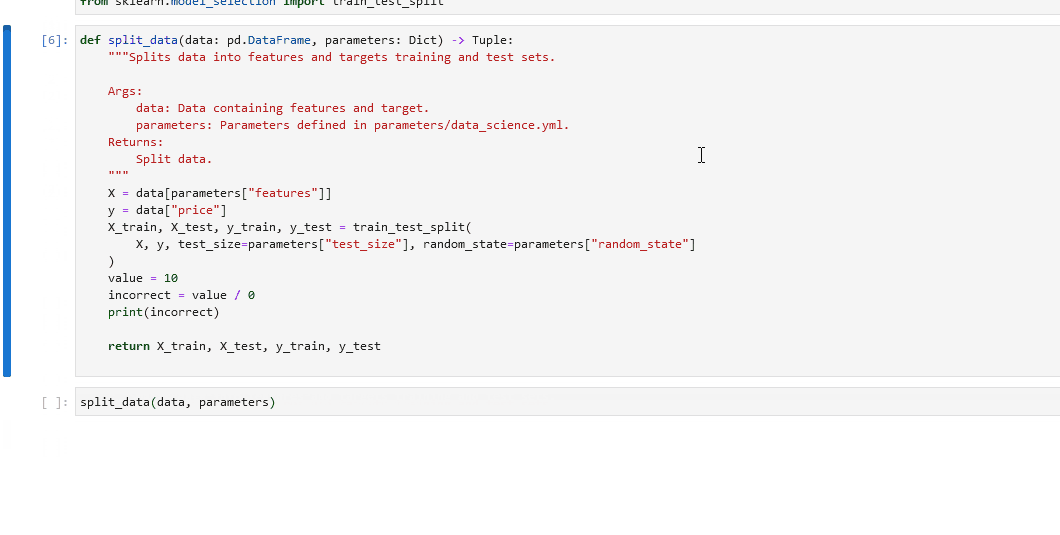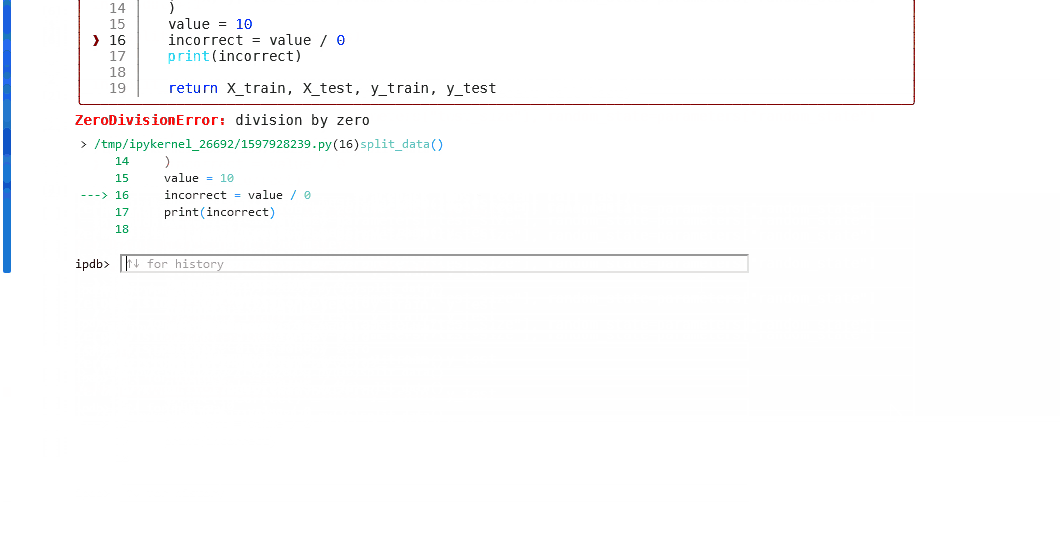
Here is example debugging workflow after discovering a node in your pipeline is failing:
Inspect the logs to find the name of the failing node. We can see below the problematic node is
split_data_node.
Click to the pipeline failure logs.
In your notebook, run
%load_node <name-of-failing-node>to load the contents of the problematic node with the%load_nodeline magic.Run the populated cells to examine the node’s behaviour in isolation.
If the node fails in error, use
%debugto launch an interactive debugging session in your notebook.
Click to see this workflow in action.
Note
The %load_node line magic is currently only available for Jupyter Notebook (>7.0) and Jupyter Lab. If you are working within a different interactive environment, manually copy over the contents from your project files instead of using %load_node to automatically populate your node’s contents, and continue from step 2.
You can also set up the debugger to run automatically when an exception occurs by using the %pdb line magic. This automatic behaviour can be enabled with %pdb 1 or %pdb on before executing a program, and disabled with %pdb 0 or %pdb off.
Click to see an example.
Some examples of the possible commands that can be used to interact with the ipdb shell are as follows:
Command |
Description |
|---|---|
|
Show the current location in the file |
|
Show a list of commands, or find help on a specific command |
|
Quit the debugger and the program |
|
Quit the debugger, continue in the program |
|
Go to the next step of the program |
|
Repeat the previous command |
|
Print variables |
|
Step into a subroutine |
|
Return out of a subroutine |
|
Insert a breakpoint |
|
Print the argument list of the current function |
For more information, use the help command in the debugger, or take at the ipdb repository for guidance.
Useful to know (for advanced users)¶
Each Kedro project has its own Jupyter kernel so you can switch between Kedro projects from a single Jupyter instance by selecting the appropriate kernel.
To ensure that a Jupyter kernel always points to the correct Python executable, if one already exists with the same name kedro_<package_name>, then it is replaced.
You can use the jupyter kernelspec set of commands to manage your Jupyter kernels. For example, to remove a kernel, run jupyter kernelspec remove <kernel_name>.
IPython, JupyterLab and other Jupyter clients¶
You can also connect an IPython shell to a Kedro project kernel as follows:
kedro ipython
The command launches an IPython shell with the extension already loaded and is the same command as ipython --ext kedro.ipython. You first saw this in action in the spaceflights tutorial.
Similarly, the following creates a custom Jupyter kernel that automatically loads the extension and launches JupyterLab with this kernel selected:
kedro jupyter lab
You can use any other Jupyter client to connect to a Kedro project kernel such as the Qt Console, which can be launched using the kedro_iris kernel as follows:
jupyter qtconsole --kernel=kedro_iris
This will automatically load the Kedro IPython in a console that supports graphical features such as embedded figures:
